AWS RDS Data API Deep Dive 🤿
Exploring how to use the AWS RDS Data API to run SQL queries on Amazon Aurora databases over HTTPS.

In a recent post I explained why the AWS RDS Data API makes bastion servers redundant. In this post we will explore how to use the RDS Data API.
The Data API allows you to run SQL queries against Amazon Aurora databases over HTTPS. No jump box needed. The API is available for both MySQL and PostgreSQL flavours of Aurora. In this post we will be using PostgreSQL. Many of the examples will work with either engine.
Prerequisites
Before we can use the Data API, we need to configure our environment. You will need the following items in place:
- Data API enabled for your Aurora cluster
- Credentials stored in Secrets Manager
- Permissions configured so your user can access the database, secret and underlying KMS key/s
If you’re missing any of these, jump to the enabling the Data API section at the end of the post.
AWS Console
The easiest way to access the RDS Data API is via the query editor in the AWS console. Before you start you will need the ARN of the secret containing your credentials. Once you have that you can connect to your database like in the example below.
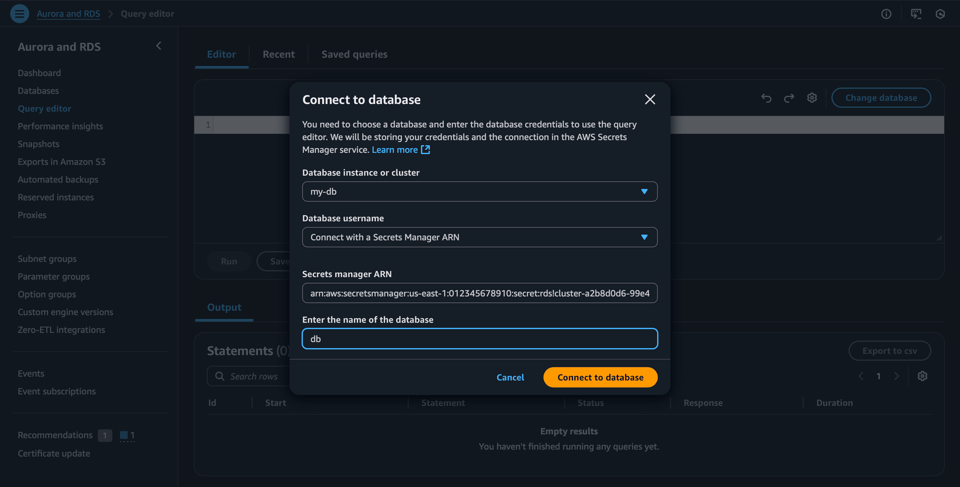
Once connected we can run a query, like so.
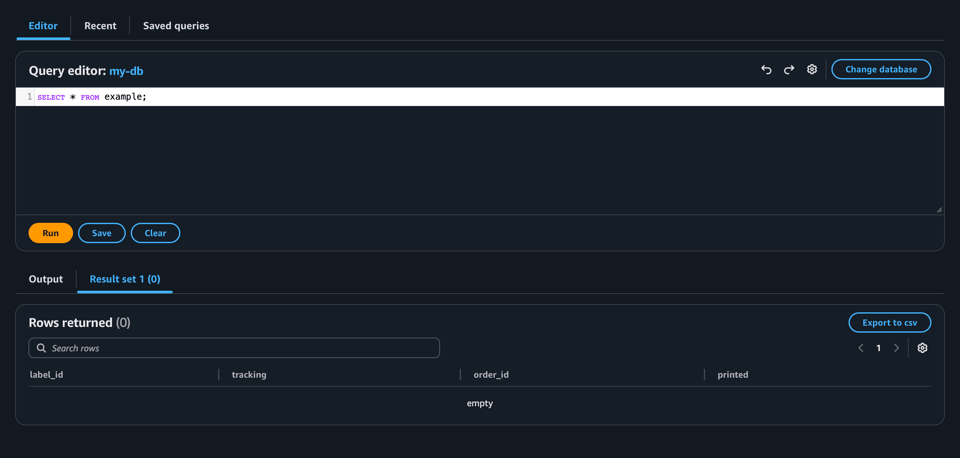
Python SDK
Calling the Data API from the console is good for debugging during an incident, but that isn’t the only use case. It is often easier to use Python for more complex queries. If you prefer another language, all variants of the AWS SDK support the RDS Data API.
If Typescript is more your thing, then try Jeremy Daly's Data API Client.
All of these examples assume that you have your environment configured to connect to AWS. Further you need the following environment variables configured:
DB_ARNfor your RDS cluster ARNSECRET_ARNwith the ARN of the Secrets Manager secret containing the database credentials
Simple SELECT
If you’re using Python, you can call the execute_statement() method of the RDS Data client. A simple call looks something like this:
#!/usr/bin/env python3
"""Run a simple SELECT query using the RDS Data API."""
import json
import os
import boto3
rds_client = boto3.client("rds-data")
result = rds_client.execute_statement(
resourceArn=os.environ["DB_ARN"],
secretArn=os.environ["SECRET_ARN"],
database="my-db",
sql="SELECT COUNT(*) FROM example;",
formatRecordsAs="JSON", # Returns result as a string encoded JSON object
)
records = json.loads(result["formattedRecords"])
print(records[0])
This should output the number of rows in your table. In my case I got the following result:
{'count': 42}
Simple INSERT
We have retrieved data from our database. Now we will insert a single record. In this example we’re going to hardcode the whole statement.
#!/usr/bin/env python3
"""Blindly insert data into an Aurora Database."""
import os
import boto3
rds_client = boto3.client("rds-data")
result = rds_client.execute_statement(
resourceArn=os.environ["DB_ARN"],
secretArn=os.environ["SECRET_ARN"],
database="my-db",
sql="INSERT INTO example (tracking, order_id, printed) VALUES ('F3E0D64AD9', 1000, 1759672881);",
)
Parameterised Query
Generally our input isn’t fixed. We need to execute queries with dynamic data from an external source. The RDS Data API supports parameterised queries. Instead of building our query by interpolating values into a string, we can parameterise our query. This helps prevent SQL injection vulnerabilities in our applications.
Adding parameters to a query string is straight forward. The tokens use the :something format, where something is the name of the variable. It is best to use the column name here. If casting is required, then this is appended to the end of the name. For example if I had a column called embeddings with a type of vector, then my token would be :embeddings::vector. The : indicates it is a token, embeddings is the name and ::vector tells PostgreSQL is a vector type.
The syntax for supplying the parameters to the query is more convoluted. Each parameter is a data structure in a list. In the snippet below we have 3 parameters replacing the fixed values from the earlier example:
rds_client.execute_statement(
resourceArn=os.environ["DB_ARN"],
secretArn=os.environ["SECRET_ARN"],
database="my-db",
sql="INSERT INTO example (tracking, order_id, printed) VALUES (:tracking, :order_id, :printed)",
parameters=[
{
"name": "tracking",
"value": {"stringValue": record["tracking"]},
},
{
"name": "order_id",
"value": {"longValue": record["order_id"]},
},
{
"name": "printed",
"value": {"longValue": record["printed"]},
},
],
)
Each parameter is a dict. The name matches the token in the SQL string. The value is a dict with the data type and value. The allowed types are arrayValue, blobValue, booleanValue, doubleValue, longValue, and stringValue for lists, base 64 encoded binary data, booleans, double-precision floating point numbers, integers, and strings respectively. isNull is set to true when a value should be set to null. The AWS RDS Data API Field documentation provides additional information.
Reading Data and INSERTing
Let’s look at a more elaborate example using a parameterised query. We pull JSON lines (JSONL) data from a file on our local machine. We can use the Data API to insert the records into the database.
Each record in the file looks like this:
{
"order_id": 1009,
"tracking": "D7A5C2F8E4",
"printed": "2025-09-19T09:41:37Z",
"status": "PRINTED"
}
The Python script below will read the file and insert records into the database.
#!/usr/bin/env python3
"""Example inserting records into Aurora DB using Data API."""
import datetime
import json
import os
import sys
import time
from collections.abc import Iterator
import boto3
import botocore
RDS_CLIENT = boto3.client("rds-data")
def insert_record(record: dict[str, str | int]) -> None:
"""Insert record into database."""
try:
RDS_CLIENT.execute_statement(
resourceArn=os.environ["DB_ARN"],
secretArn=os.environ["SECRET_ARN"],
database="my-db",
sql="INSERT INTO example (tracking, order_id, printed) VALUES (:tracking, :order_id, :printed)",
parameters=[
{
"name": "tracking",
"value": {"stringValue": record["tracking"]},
},
{
"name": "order_id",
"value": {"longValue": record["order_id"]},
},
{
"name": "printed",
"value": {"longValue": record["printed"]},
},
],
)
# Basic catch all error handler.
except botocore.exceptions.ClientError as e:
print(f"CLIENT ERROR: {e}")
exit(1)
def get_records(data_file: str) -> Iterator[dict[str, str | int]]:
"""Load records from JSONL file."""
with open(data_file) as f:
for line in f:
record = json.loads(line)
yield {
"order_id": int(record["order_id"]),
"tracking": record["tracking"],
"printed": int(
datetime.datetime.fromisoformat(record["printed"]).timestamp()
),
}
def main(data_file: str) -> None:
"""Process the data file and save the records to the database."""
records = 0
for record in get_records(data_file):
insert_record(record)
records += 1
print(f"Inserted {records} records.")
if __name__ == "__main__":
main(sys.argv[1])
These examples really just scratch the surface of using Python to call the RDS Data API. For more details of what is possible, check out the official documentation. There you will find more information and more advanced use cases including transactions and batch processing.
Batch Operations
Rather than inserting each record separately, we can use the BatchExecuteStatement endpoint to submit multiple records at the same time. When calling this endpoint, total size of the payload must not exceed 4MiB, including any headers.
I refactored the example above to use the batch endpoint. Now it inserts records in batches of 100. This avoids exceeding the maximum payload size. This avoids the overhead of loading the secret for each record and the number of queries executed, thus reducing costs. Here is the code:
#!/usr/bin/env python3
"""Example batch inserting records into Aurora DB using Data API."""
import datetime
import json
import os
import sys
from collections.abc import Iterator
import boto3
import botocore
# Arbitrary number to demonstrate one way of avoiding exceeding maximum payload size of 4MiB
MAX_INSERT = 100
RDS_CLIENT = boto3.client("rds-data")
def insert_records(records: list[list[dict[str, str | int]]]) -> None:
"""Insert record into database."""
try:
RDS_CLIENT.batch_execute_statement(
resourceArn=os.environ["DB_ARN"],
secretArn=os.environ["SECRET_ARN"],
database="my-db",
sql="INSERT INTO example (tracking, order_id, printed) VALUES (:tracking, :order_id, :printed)",
parameterSets=records,
)
except botocore.exceptions.ClientError as e:
print(f"CLIENT ERROR: {e}")
exit(1)
def get_records(data_file: str) -> Iterator[dict[str, str | int]]:
"""Load records from JSONL file."""
with open(data_file) as f:
for line in f:
record = json.loads(line)
yield {
"order_id": int(record["order_id"]),
"tracking": record["tracking"],
"printed": int(
datetime.datetime.fromisoformat(record["printed"]).timestamp()
),
}
def prepare_record(raw_record: dict[str, str | int]) -> list[dict[str, str | int]]:
"""Convert a raw record into parameters for RDS Data API."""
return [
{
"name": "tracking",
"value": {"stringValue": raw_record["tracking"]},
},
{
"name": "order_id",
"value": {"longValue": raw_record["order_id"]},
},
{
"name": "printed",
"value": {"longValue": raw_record["printed"]},
},
]
def main(data_file: str) -> None:
"""Process the data file and save the records to the database."""
cnt = 0
records = []
for record in get_records(data_file):
records.append(prepare_record(record))
cnt += 1
if cnt % MAX_INSERT == 0:
insert_records(records)
records = []
if records: # Insert remaining records
insert_records(records)
print(f"Inserted {cnt} records.")
if __name__ == "__main__":
main(sys.argv[1])
In this example I introduced some some basic error handling. For production usage you should implement comprehensive error handling and retry logic.
Transactions
While transactions are rarely used when performing troubleshooting or administrative tasks, the Data API supports them via the BeginTransaction, CommitTransaction, and RollbackTransaction endpoints. The AWS Python SDK exposes these endpoints too. Below is a quick example of how to implement transactions using the Data API.
#!/usr/bin/env python3
"""Insert data into an Aurora database using a transaction."""
import os
import boto3
import botocore
rds_client = boto3.client("rds-data")
# Start the transaction
txn = rds_client.begin_transaction(
resourceArn=os.environ["DB_ARN"],
secretArn=os.environ["SECRET_ARN"],
database="my-db",
)
try:
rds_client.execute_statement(
resourceArn=os.environ["DB_ARN"],
secretArn=os.environ["SECRET_ARN"],
database="my-db",
sql="INSERT INTO example (tracking, order_id, printed) VALUES ('F3E0D64AD9', 1000, 1759672881);",
transactionId=txn[
"transactionId"
], # Indicate operation is part of a transaction
)
# Any additional queries go here
except botocore.exceptions.ClientError as e:
print(f"ERROR: {e}")
abort_response = rds_client.rollback_transaction(
resourceArn=os.environ["DB_ARN"],
secretArn=os.environ["SECRET_ARN"],
# database is not used in this call
transactionId=txn["transactionId"],
)
print(abort_response["transactionStatus"])
exit(1)
# If there are no errors, commit the transaction
commit_response = rds_client.commit_transaction(
resourceArn=os.environ["DB_ARN"],
secretArn=os.environ["SECRET_ARN"],
# database is not used in this call either
transactionId=txn["transactionId"], # Reference the transaction to commit
)
print(commit_response["transactionStatus"])
If you need to use transactions in your code, refer the documentation for more information.
Cold Starts
Aurora Serverless is great when you have uneven traffic patterns. For production workloads it is common to have a level minimum capacity provisioned so the database is always running. For non production environments the minimum is often set to zero. This is great for cost savings. The downside is that it takes a few seconds for the server to relaunch.
To handle this delay we need some additional logic. Let’s update our SELECT example. We add a new function - wait_for_db() . We will call this function before querying the database. This ensures the server is running before we try to execute our real query.
#!/usr/bin/env python3
"""Run a simple SELECT query on Aurora Serverless Database."""
import json
import os
import time
import boto3
import botocore
# Generally the database takes 5-15s to become available
DB_MAX_CHECKS = 6
DB_WAIT = 3
RDS_CLIENT = boto3.client("rds-data")
def wait_for_db() -> None:
"""Wait for Aurora Serverless to relaunch."""
print("Checking database connection...")
attempt = 0
while attempt <= DB_MAX_CHECKS:
try:
attempt += 1
RDS_CLIENT.execute_statement(
resourceArn=os.environ["DB_ARN"],
secretArn=os.environ["SECRET_ARN"],
database="my-db",
sql="SELECT NOW();",
)
# When DB is relaunching
except RDS_CLIENT.exceptions.DatabaseResumingException:
print("Waiting for server to resume...")
time.sleep(DB_WAIT)
# Other AWS errors
except botocore.exceptions.ClientError as e:
print(f"ERROR: {e}")
exit(1)
else:
return # We can't get here if an exception is thrown
print("ERROR: Database failed to restart!")
exit(1)
wait_for_db()
result = RDS_CLIENT.execute_statement(
resourceArn=os.environ["DB_ARN"],
secretArn=os.environ["SECRET_ARN"],
database="my-db",
sql="SELECT COUNT(*) FROM example;",
formatRecordsAs="JSON",
)
records = json.loads(result["formattedRecords"])
print(records[0]["count"])
AWS CLI
Earlier we looked at counting records in the database using Python. We can do the same using the AWS CLI.
aws rds-data execute-statement --resource-arn "$DB_ARN" --secret-arn "$SECRET_ARN" --database my-db --sql 'SELECT COUNT(*) FROM example' --query 'records[0][0].longValue'
In theory it is possible to run more complex queries from the command line. In practice escaping JSON gets complicated. The nested object structure for parameterised queries can get messy. Generally, I would recommend using Python, or another supported language for most operations. The execute-statement command is available in the AWS CLI when you really need it.
Look Ma No Low Code
Step Functions has built in integrations with hundreds of AWS endpoints. This includes the RDS Data API ExecuteStatement endpoint. This allows us to run queries in a Step Function. Here is a quick example of inserting the same records from our Python example in a Step Functions workflow.
We can call the Step Function with the following payload:
{
"Record": {
"order_id": 1009,
"tracking": "D7A5C2F8E4",
"printed": "2025-09-19T09:41:37Z",
"status": "PRINTED"
}
}
Here is the Step Function definition:
{
"Comment": "Insert record into database",
"QueryLanguage": "JSONata",
"StartAt": "RecordData",
"States": {
"RecordData": {
"Type": "Task",
"Arguments": {
"ResourceArn": "arn:aws:rds:us-east-1:012345678910:cluster:my-db",
"SecretArn": "arn:aws:secretsmanager:us-east-1:012345678910:secret:rds!cluster-a2b8d0d6-99e4-4d31-9918-ee61037c3849-Xdyn3a",
"Database": "my-db",
"Sql": "INSERT INTO example (tracking, order_id, printed) VALUES (:tracking, :order_id, :printed)",
"Parameters": [
{
"Name": "tracking",
"Value": {
"StringValue": "{% $states.input.Record.tracking %}"
}
},
{
"Name": "order_id",
"Value": {
"LongValue": "{% $states.input.Record.order_id %}"
}
},
{
"Name": "printed",
"Value": {
"LongValue": "{% $toMillis($states.input.Record.printed)/1000 /* $toMillis() returns milliseconds since epoch, we need seconds */ %}"
}
}
]
},
"Resource": "arn:aws:states:::aws-sdk:rdsdata:executeStatement",
"Retry": [
{
"ErrorEquals": [
"RdsData.DatabaseResumingException",
"RdsData.DatabaseUnavailableException",
"RdsData.RdsDataException"
],
"IntervalSeconds": 5,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"End": true
}
}
}
Even though this is a JSON file defining the workflow, you should be able to see the similarities with the other examples. Under the hood it is calling the same API each time.
After invoking our Step Function, the screenshot confirms our record was inserted into the database.

Refer to the bonus setup section at the end of this post to configure the permissions for the Step Function.
CloudTrail Integration
The RDS Data API supports query logging via CloudTrail, but logging of these data events is not enabled by default. This gives you useful insights not available from traditional clients. The logs don’t capture the details of the query. The logs record that someone ran a query but the contents of query, database and schema are redacted by CloudTrail with **********. Once enabled the logging records all queries performed via the Data API. CloudTrail doesn't care about the source.
The insert query was captured by CloudTrail and stored in a logging bucket. You can see below an abridged version of the logged event.
{
"Records": [
{
"eventVersion": "1.11",
"userIdentity": {...},
....
"requestParameters": {
"resourceArn": "arn:aws:rds:us-east-1:012345678910:cluster:my-db",
"secretArn": "arn:aws:secretsmanager:us-east-1:012345678910:secret:rds!cluster-a2b8d0d6-99e4-4d31-9918-ee61037c3849-Xdyn3a",
"sql": "**********",
"database": "**********",
"schema": "**********",
"parameters": [],
"includeResultMetadata": true,
"continueAfterTimeout": true
},
...
}
]
}
There is enough information in the logs to identify anomalies and trigger investigations if required.
Limitations of the Data API
The RDS Data API isn’t perfect. There are times when it isn’t a great fit.
The API can only handle responses up to 1MiB and individual rows of data up to 64Kb. This can often be mitigated by paging through results and limiting the columns in SELECT statements.
Some data types aren’t supported. Amazon suggests using CAST() to overcome this issue.
Data API operations must complete within 45 seconds. INSERTs and DDL operations may take longer. In these cases, set the continueAfterTimeout to true. The operations will continue in the background. The downside is you won’t know if the operation errored after the API returns.
Heavy use can result in a surprise when you get your next bill. At the time of writing Data API requests range from 0.20 to 0.70USD per million requests, depending on the region and volume of requests. In reality using the Data API for administrative tasks is likely to cost pennies per month. In us-east-1, running a t4g.micro on demand instance as a bastion costs ~6.05USD p/mth (0.0084 * 720hrs). It would take over 17 million Data API calls before you pay 6.05USD (6.05 / 0.35 p/million calls). In Brazil the bastion costs 9.65USD per month (0.0134 * 720) and API calls cost 0.70 USD per million, meaning you would still need almost 14 million API calls (9.65/0.70) a month before the bastion was cheaper. These numbers exclude the maintenance costs associated with bastions.
The RDS Data API availability varies by Aurora version and region. Availability is growing, so check the status of your region.
Native database clients are more performant than the Data API. The Data API adds around 100-300ms per request because of the HTTPS overhead and the need to fetch the credentials from Secrets Manager. Direct database connections typically have sub 10ms latency. The Data API is better suited to administrative tasks and low-frequency operations, rather than latency sensitive applications.
AWS provides detailed notes on the limitations of the Data API if you want more detail.
Wrap Up
The AWS RDS Data API isn’t a complete replacement for native database clients. It is another tool in your toolkit. It is especially useful for ad hoc administration queries. Low traffic applications could benefit from the simplicity of the Data API, but most applications will continue to use the native database client library for querying the database.
The RDS Data API allows you to run queries against your database from outside the VPC. This means you don’t need a bastion server for remote access to the database. For many, the query editor will be sufficient for accessing the database from outside of the VPC. More complex operations can be performed via one of the various AWS SDKs, such as Python.
IAM controls who can run queries. Users and applications with the appropriate permissions can run queries. They can use any of supported tools including the Query Editor, AWS SDKs, AWS CLI or Step Functions. This provides a lot of flexibility for accessing the database in different scenarios.
To improve security of your AWS environment, consider replacing bastion access to your database with RDS Data API.
Bonus: Enabling Data API
This is a quick guide on how to enable the RDS Data API for your cluster and users.
Enable API
First up we need to ensure the Data API is enabled for our cluster. It is not enabled by default. If you want to use ClickOps to turn it on, follow the AWS guide. For those of you using Terraform, you can set enable_http_endpoint to true for your aws_rds_cluster resource. It is similar for CloudFormation. Set EnableHttpEndpoint to true.
Credentials
Next up we need to make sure we have a secret configured in Secrets Manager. You can
create a secret manually with your existing credentials. For new clusters you can automagically store your admin credentials in Secrets Manager. For Terraform, set manage_master_user_password to true . Set ManageMasterUserPassword to true in your CloudFormation stack. You can make the same configuration change for existing clusters. This will change the existing admin user’s password. Remember to take a snapshot before making a change like this.
Permissions
Finally we need to ensure our user can access the secret, the encryption key for the secret and the database. If you’re like at least half of my readers you’ll be using an admin user, so you won’t need to worry. If you want to implement least privileged access, use the following IAM policy for your user:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"rds-data:ExecuteStatement"
],
"Resource": [
"arn:aws:rds:us-east-1:012345678910:cluster:CLUSTER_ID"
]
},
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret"
],
"Resource": "arn:aws:secretsmanager:us-east-1:012345678910:secret:SECRET_NAME"
},
{
"Effect": "Allow",
"Action": "kms:Decrypt",
"Resource": "arn:aws:kms:us-east-1:012345678910:key/KEY_ID"
}
]
}
Make sure you update the referenced ARNs to reflect your environment. Now you’re ready to start using the Data API. 🌊