Amazon EventBridge as Your Proactive Ops Engine
In this post I explore why Amazon EventBridge should be a central component of your Proactive Ops platform.
 One of the key activities in Proactive Ops is analysing events to identify potential issues and remediating them without human intervention. These events need to be collected and routed to handlers. If you are building your Proactive Ops platform on AWS, Amazon’s EventBridge (nee Amazon CloudWatch Events) is a foundational component of your tech stack.
One of the key activities in Proactive Ops is analysing events to identify potential issues and remediating them without human intervention. These events need to be collected and routed to handlers. If you are building your Proactive Ops platform on AWS, Amazon’s EventBridge (nee Amazon CloudWatch Events) is a foundational component of your tech stack.
Rather than bore you with all the detail of AWS EventBridge, I will give you a quick run through of the key features. EventBridge is a managed scalable service bus that includes the following features:
- Native integrations with over 200 Amazon services, as well as third party SaaS products and your own applications
- Powerful filtering and routing of events
- Event routing between AWS regions and accounts
- Event archiving and replay for backfilling new services and recovering from failures
- Dead letter queues for handling undeliverable events
- Schema Registry for capturing and sharing event structure data between teams
- Integration with X-Ray for distributed tracing and observability
There is so much to learn about EventBridge that I can’t cover it all in this post. When David Boyne releases his book Amazon EventBridge: The Definitive Guide, grab a copy. In the mean time, check out the official Amazon EventBridge documentation for all the stuff I skipped.
Patterns, Rules and Targets
AWS splits the configuration for routing events on an EventBridge bus into two parts - rules and targets.
An EventBridge rule wraps a matching pattern expressed as a JSON object. The pattern tells the bus which events to select. Amazon provides a growing set of operators for matching events. While it is is tempting to build complex patterns, this can make debugging problems difficult. It is simpler for a handler to discard a few events it doesn’t care about, rather than performing deep analysis of every event passing through the bus.
A pattern is only attached to a single bus. When a same pattern is needed on multiple buses, the configuration must be duplicated.
Once a rule matches an event, the bus routes it to the configured targets. At the time of writing, EventBridge supports around 30 targets. The most common targets are lambda functions, other buses, step functions, SQS queues and API destinations. Targets can remap event objects using input transformations. This is particularly useful when interacting with legacy systems or third party applications.
A single rule can have multiple targets. However, this is generally discouraged as it introduces coupling between targets. It is easier to maintain rules where there is a one to one mapping with a target. This means that any change to a rule won’t have unintended effects on the other targets.
Distributed EventBridge Architecture
It is tempting to just jump in and start using the default bus provisioned by Amazon. Don’t do this. The default bus should only be used for events emitted by Amazon’s managed services. This keeps different types of events separated. Moving from putting events on one bus to another gets messy. Avoid that from the start.
Stephen Liedig’s presentation at re:Invent 2020 discusses various patterns for managing buses and the trade offs of each. This is an excellent presentation if you want to explore the various architectures.
If you only have a small number of services or applications, it is tempting to share a bus between them. Once again, the easy path invites trouble later. Build for what you need now, but design for two orders of magnitude in scale. The most scalable option is the distributed multiple bus pattern, ideally with multiple accounts.
Amazon allows 100 buses per region, per account. That is more than enough for most teams. Allocate a bus per application or service. Make each team responsible for their own bus. The bus is an interface of the service.
Avoid teams collaborating, and colliding, on a shared buses. Separate buses increases team autonomy. Sharing resources often leads to a lack of ownership and responsibility.
Types of Buses
In their documentation, Amazon refers to 3 different types of EventBridge buses - default, custom and partner. The default bus is the one that carries events emitted by AWS Services. Amazon customers provision custom buses. Third party SaaS vendors integrate with EventBridge via partner buses.
Amazon terminology is useful for understanding the integration types, but it doesn’t explain the purpose of a bus. Aligning on names assists with collaboration within and between teams. When talking about buses, understanding the purpose rather than the Amazon integration type is more useful.
The default bus or as I prefer to call it - the AWS bus - only handles events from Amazon services. There’s not much else to say about this bus.
In an ideal world every SaaS product would provide an EventBridge integration. The world isn’t perfect, so many companies don’t provide this integration. If we’re lucky, a product will implement webhooks for emitting events. We can then create a Lambda function URL to capture events and feed them into a dedicated bus. Regardless of if the integration is native or custom built, I refer to buses handling events from third party services as an “inbound bus”.
An inbound bus only receives and routes events. These buses should only talk to other buses, not Lambda functions or other handlers. This makes it easy for a team to manage the bus and the routing, without having to worry about other team’s workloads. Where possible, these buses should live in a separate account. This way they get all of the event quota without having to worry about noisy neighbours.
When a bus is connected to a service or application, I give it the label app bus. This bus has rules to route events to the application and events emitted by the application are put on this bus. When another application needs to consume events put onto an app bus, rules are added to route events from the source app bus to the target app bus. This keeps the boundaries of each application clean.
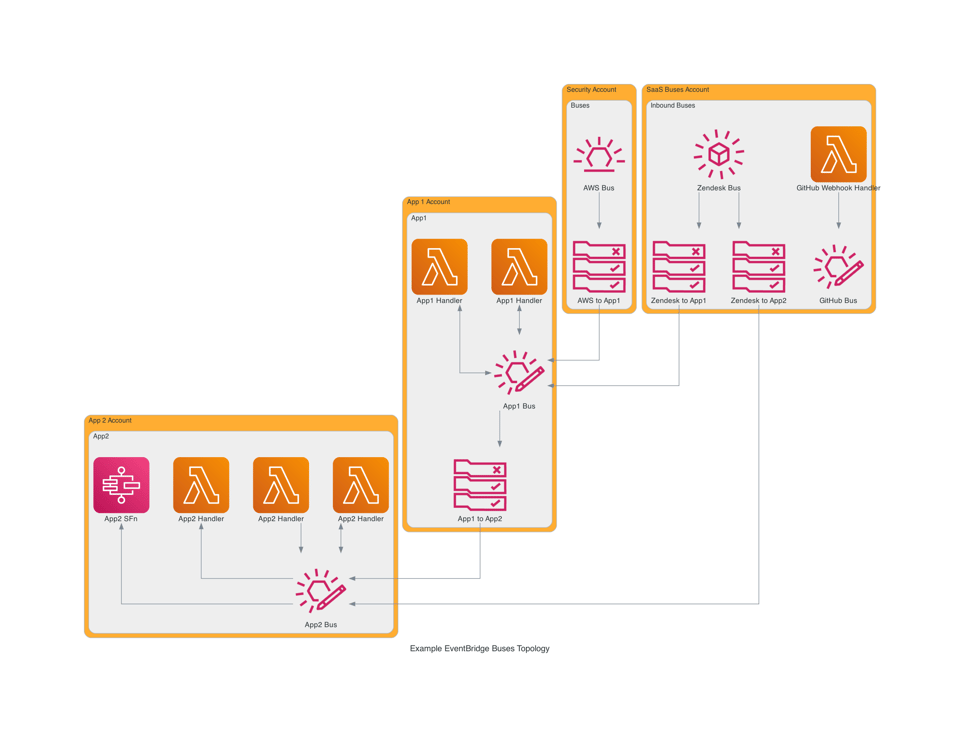
Routing Between Buses
Giving each application or service an app bus can lead to dozens or even hundreds of buses being provisioned. Managing the routing between all of the buses might seem complicated - it can be. When done right, it doesn’t need to be.
When a team needs an event routed from one bus to another, they need to provision the same resources every time - rule, target, IAM role, and update the resource policy on the receiving bus. If you insist on deploying via ClickOps, this is a slow and tedious process. On the other hand, it’s this consistency that keeps the configuration simple. Infrastructure as code tools such as Terraform are built for managing consistent configuration.
With Terraform we can create a module that software engineers can use for configuring routing between buses. An engineer should be able to provide an event pattern and a target bus, and then Terraform takes care of provisioning all the resources. It should be just as easy to allow events in from another bus.
Simplifying Management with EventBus++
Managing a large number of buses can be difficult. Today I’m releasing EventBus++ for Terraform. This Terraform module deploys an AWS EventBridge event bus, along with configuration to manage sending and receiving events from other buses. Now teams can quickly and reliably configure rules and permissions for sending events between buses. The module includes support for logging events to CloudWatch Logs to assist with debugging rules and configuring dead letter queues (DLQs) for failed messages. The module supports custom app buses and “inbound” buses, including partner buses.
The intention of this module is to focus on managing the bus and routing between buses. While it would be possible to build out the feature set so it becomes a Swiss Army knife for EventBridge, that isn’t the intention. Such a module would be complicated, which brings its own issues. The aim is to have a dead simple module for creating buses and configuring the routing between them.
Check out EventBus++ on GitHub. If you experience any problems, please open an issue. 🌊